Search Reference
Note on search 2.0 vs. legacy search
This document refers to Riak search 2.0 with Solr integration (codenamed Yokozuna). For information about the deprecated Riak search, visit the old Using Riak search docs.
The project that implements Riak search is codenamed Yokozuna. This is a more detailed overview of the concepts and reasons behind the design of Yokozuna, for those interested. If you’re simply looking to use Riak search, you should check out the Using Search document.
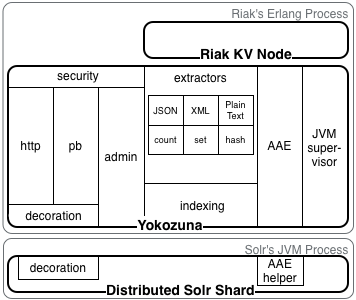
Riak Search is Erlang
In Erlang OTP, an “application” is a group of modules and Erlang processes which together perform a specific task. The word application is confusing because most people think of an application as an entire program such as Emacs or Photoshop. But Riak Search is just a sub-system in Riak itself. Erlang applications are often stand-alone, but Riak Search is more like an appendage of Riak. It requires other subsystems like Riak Core and KV, but also extends their functionality by providing search capabilities for KV data.
The purpose of Riak Search is to bring more sophisticated and robust query and search support to Riak. Many people consider Lucene and programs built on top of it, such as Solr, as the standard for open-source search. There are many successful applications built on Lucene/Solr, and it sets the standard for the feature set that developers and users expect. Meanwhile, Riak has a great story as a highly-available, distributed key/value store. Riak Search takes advantage of the fact that Riak already knows how to do the distributed bits, combining its feature set with that of Solr, taking advantage of the strengths of each.
Riak Search is a mediator between Riak and Solr. There is nothing stopping a user from deploying these two programs separately, but this would leave the user responsible for the glue between them. That glue can be tricky to write. It requires dealing with monitoring, querying, indexing, and dissemination of information.
Unlike Solr by itself, Riak Search knows how to do all of the following:
- Listen for changes in key/value (KV) data and to make the appropriate changes to indexes that live in Solr. It also knows how to take a user query on any node and convert it to a Solr distributed search, which will correctly cover the entire index without overlap in replicas.
- Take index creation commands and disseminate that information across the cluster.
- Communicate and monitor the Solr OS process.
Solr/JVM OS Process
Every node in a Riak cluster has a corresponding operating system (OS) process running a JVM which hosts Solr on the Jetty application server. This OS process is a child of the Erlang OS process running Riak.
Riak Search has a gen_server process which monitors the JVM OS
process. The code for this server is in yz_solr_proc. When the JVM
process crashes, this server crashes, causing its supervisor to restart
it.
If there is more than 1 restart in 45 seconds, the entire Riak node will be shut down. If Riak Search is enabled and Solr cannot function for some reason, the Riak node needs to go down so that the user will notice and take corrective action.
Conversely, the JVM process monitors the Riak process. If for any reason Riak goes down hard (e.g. a segfault) the JVM process will also exit. This double monitoring along with the crash semantics means that neither process may exist without the other. They are either both up or both down.
All other communication between Riak Search and Solr is performed via
HTTP, including querying, indexing, and administration commands. The
ibrowse Erlang HTTP client is used to manage these communications as
both it and the Jetty container hosting Solr pool HTTP connections,
allowing for reuse. Moreover, since there is no gen_server involved in
this communication, there’s no serialization point to bottleneck.
Indexes
An index, stored as a set of files on disk, is a logical namespace that contains index entries for objects. Each such index maintains its own set of files on disk—a critical difference from Riak KV, in which a bucket is a purely logical entity and not physically disjoint at all. A Solr index requires significantly less disk space than the corresponding legacy Riak Search index, depending on the Solr schema used.
Indexes may be associated with zero or more buckets. At creation time, however, each index has no associated buckets—unlike the legacy Riak Search, indexes in the new Riak Search do not implicitly create bucket associations, meaning that this must be done as a separate configuration step.
To associate a bucket with an index, the bucket property search_index must
be set to the name of the index you wish to associate. Conversely, in
order to disassociate a bucket you use the sentinel value
_dont_index_.
Many buckets can be associated with the same index. This is useful for logically partitioning data into different KV buckets which are of the same type of data, for example if a user wanted to store event objects but logically partition them in KV by using a date as the bucket name.
A bucket cannot be associated with many indexes—the search_index
property must be a single name, not a list.
See the main Search documentation for details on creating an index.
Extractors
There is a tension between Riak KV and Solr when it comes to data. Riak KV treats object values as mostly opaque, and while KV does maintain an associated content type, it is simply treated as metadata to be returned to the user to provide context for interpreting the returned object. Otherwise, the user wouldn’t know what type of data it is!
Solr, on the other hand, wants semi-structured data, more specifically a flat collection of field-value pairs. “Flat” here means that a field’s value cannot be a nested structure of field-value pairs; the values are treated as-is (non-composite is another way to say it).
Because of this mismatch between KV and Solr, Riak Search must act as a mediator between the two, meaning it must have a way to inspect a KV object and create a structure which Solr can ingest for indexing. In Solr this structure is called a document. This task of creating a Solr document from a Riak object is the job of the extractor. To perform this task two things must be considered.
Note: This isn’t quite right, the fields created by the extractor
are only a subset of the fields created. Special fields needed for
Yokozuna to properly query data and tagging fields are also created.
This call happens inside yz_doc:make_doc.
- Does an extractor exist to map the content-type of the object to a Solr document?
- If so, how is the object’s value mapped from one to the other?
For example, the value may be
application/jsonwhich contains nested objects. This must somehow be transformed into a flat structure.
The first question is answered by the extractor mapping. By default Yokozuna ships with extractors for several common data types. Below is a table of this default mapping:
| Content Type | Erlang Module |
|---|---|
application/json |
yz_json_extractor |
application/xml |
yz_xml_extractor |
text/plain |
yz_text_extractor |
text/xml |
yz_xml_extractor |
| N/A | yz_noop_extractor |
The answer to the second question is a function of the implementation of the extractor module. Every extractor must conform to the following Erlang specification:
-spec(ObjectValue::binary(), Options::proplist()) -> fields() | {error, term()}.
-type field_name() :: atom() | binary().
-type field_value() :: binary().
-type fields() :: [{field_name(), field_value()}]
The value of the object is passed along with options specific to each extractor. Assuming the extractor correctly parses the value it will return a list of fields, which are name-value pairs.
The text extractor is the simplest one. By default it will use the
object’s value verbatim and associate if with the field name text.
For example, an object with the value “How much wood could a woodchuck
chuck if a woodchuck could chuck wood?” would result in the following
fields list.
[{text, <<"How much wood could a woodchuck chuck if a woodchuck could chuck wood?">>}]
An object with the content type application/json is a little trickier.
JSON can be nested arbitrarily. That is, the key of a top-level object
can have an object as a value, and this object can have another object
nested inside, an so on. Yokozuna’s JSON extractor must have some method
of converting this arbitrary nesting into a flat list. It does this by
concatenating nested object fields with a separator. The default
separator is .. An example should make this more clear.
Below is JSON that represents a person, what city they are from and what cities they have traveled to.
{
"name": "ryan",
"info": {
"city": "Baltimore",
"visited": ["Boston", "New York", "San Francisco"]
}
}
Below is the field list that would be created by the JSON extract.
[{<<"info.visited">>,<<"San Francisco">>},
{<<"info.visited">>,<<"New York">>},
{<<"info.visited">>,<<"Boston">>},
{<<"info.city">>,<<"Baltimore">>},
{<<"name">>,<<"ryan">>}]
Some key points to notice.
- Nested objects have their field names concatenated to form a field
name. The default field separator is
.. This can be modified. - Any array causes field names to repeat. This will require that your schema defines this field as multi-valued.
The XML extractor works in very similar fashion to the JSON extractor
except it also has element attributes to worry about. To see the
document created for an object, without actually writing the object, you
can use the extract HTTP endpoint. This will do a dry-run extraction and
return the document structure as application/json.
curl -XPUT http://localhost:8098/search/extract \
-H 'Content-Type: application/json' \
--data-binary @object.json
Schemas
Every index must have a schema, which is a collection of field names and types. For each document stored, every field must have a matching name in the schema, used to determine the field’s type, which in turn determines how a field’s value will be indexed.
Currently, Yokozuna makes no attempts to hide any details of the Solr schema: a user creates a schema for Yokozuna just as she would for Solr. Here is the general structure of a schema.
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="my-schema" version="1.5">
<fields>
<!-- field definitions go here -->
</fields>
<!-- DO NOT CHANGE THIS -->
<uniqueKey>_yz_id</uniqueKey>
<types>
<!-- field type definitions go here -->
</types>
</schema>
The <fields> element is where the field name, type, and overriding
options are declared. Here is an example of a field for indexing dates.
<field name="created" type="date" indexed="true" stored="true"/>
The corresponding date type is declared under <types> like so.
<fieldType name="date" class="solr.TrieDateField" precisionStep="0" positionIncrementGap="0"/>
You can also find more information on to how customize your own search schema.
Yokozuna comes bundled with a default schema
called _yz_default. This is an extremely general schema which makes
heavy use of dynamic fields—it is intended for development and
testing. In production, a schema should be tailored to the data being
indexed.
Active Anti-Entropy (AAE)
Active Anti-Entropy (AAE) is the process of discovering and correcting entropy (divergence) between the data stored in Riak’s key-value backend and the indexes stored in Solr. The impetus for AAE is that failures come in all shapes and sizes—disk failure, dropped messages, network partitions, timeouts, overflowing queues, segment faults, power outages, etc. Failures range from obvious to invisible. Failure prevention is fraught with failure, as well. How do you prevent your prevention system from failing? You don’t. Code for detection, not prevention. That is the purpose of AAE.
Constantly reading and re-indexing every object in Riak could be quite expensive. To minimize the overall cost of detection AAE make use of hashtrees. Every partition has a pair of hashtrees; one for KV and another for Yokozuna. As data is written the hashtrees are updated in real-time.
Each tree stores the hash of the object. Periodically a partition is selected and the pair of hashtrees is exchanged. First the root hashes are compared. If equal then there is no more work to do. You could have millions of keys in one partition and verifying they all agree takes the same time as comparing two hashes. If they don’t match then the root’s children are checked and this process continues until the individual discrepancies are found. If either side is missing a key or the hashes for a key do not match then repair is invoked on that key. Repair converges the KV data and its indexes, removing the entropy.
Since failure is inevitable, and absolute prevention impossible, the hashtrees themselves may contain some entropy. For example, what if the root hashes agree but a divergence exists in the actual data? Simple, you assume you can never fully trust the hashtrees so periodically you expire them. When expired, a tree is completely destroyed and the re-built from scratch. This requires folding all data for a partition, which can be expensive and take some time. For this reason, by default, expiration occurs after one week.
For an in-depth look at Riak’s AAE process, watch Joseph Blomstedt’s screencast.
Analysis & Analyzers
Analysis is the process of breaking apart (analyzing) text into a stream of tokens. Solr allows many different methods of analysis, an important fact because different field values may represent different types of data. For data like unique identifiers, dates, and categories you want to index the value verbatim—it shouldn’t be analyzed at all. For text like product summaries, or a blog post, you want to split the value into individual words so that they may be queried individually. You may also want to remove common words, lowercase words, or perform stemming. This is the process of analysis.
Solr provides many different field types which analyze data in different ways, and custom analyzer chains may be built by stringing together XML in the schema file, allowing custom analysis for each field. For more information on analysis, see Search Schema.
Tagging
Tagging is the process of adding field-value pairs to be indexed via Riak object metadata. It is useful in two scenarios.
The object being stored is opaque but your application has metadata about it that should be indexed, for example storing an image with location or category metadata.
The object being stored is not opaque, but additional indexes must be added without modifying the object’s value.
See Tagging for more information.
Coverage
Yokozuna uses doc-based partitioning. This means that all index entries for a given Riak Object are co-located on the same physical machine. To query the entire index all partitions must be contacted. Adjacent partitions keep replicas of the same object. Replication allows the entire index to be considered by only contacting a subset of the partitions. The process of finding a covering set of partitions is known as coverage.
Each partition in the coverage plan has an owning node. Thus a plan can
be thought of as a unique set of nodes along with a covering set of
partitions. Yokozuna treats the node list as physical hostnames and
passes them to Solr’s distributed search via the shards parameter.
Partitions, on the other hand, are treated logically in Yokozuna. All
partitions for a given node are stored in the same index; unlike KV
which uses partition as a physical separation. To properly filter out
overlapping replicas the partition data from the cover plan is passed to
Solr via the filter query (fq) parameter.
Calculating a coverage plan is handled by Riak Core. It can be a very expensive operation as much computation is done symbolically, and the process amounts to a knapsack problem. The larger the ring the more expensive. Yokozuna takes advantage of the fact that it has no physical partitions by computing a coverage plan asynchronously every few seconds, caching the plan for query use. In the case of node failure or ownership change this could mean a delay between cluster state and the cached plan. This is, however, a good trade-off given the performance benefits, especially since even without caching there is a race, albeit one with a smaller window.
Statistics
The Riak Search batching subsystem provides statistics on run-time characteristics of search system components. These statistics are accessible via the standard Riak KV stats interfaces and can be monitored through standard enterprise management tools.
search_index_throughput_(count|one)- The total count of objects that have been indexed, per Riak node, and the count of objects that have been indexed within the metric measurement window.search_index_latency_(min|mean|max|median|95|99|999)- The minimum, mean, maximum, median, 95th percentile, 99th percentile, and 99.9th percentile measurements of indexing latency, as measured from the time it takes to send a batch to Solr to the time the response is received from Solr, divided by the batch size.search_queue_batch_latency_(min|mean|max|median|95|99|999)- The minimum, mean, maximum, median, 95th percentile, 99th percentile, and 99.9th percentile measurements of batch latency, as measured from the time it takes to send a batch to Solr to the time the response is received from Solr.search_queue_batch_throughput_(count|one)- The total number of batches delivered into Solr, per Riak node, and the number of batches that have been indexed within the metric measurement window.search_queue_batchsize_(min|mean|max|median)- The minimum, mean, maximum, and median measurements of the batch size across all indices and Solrq worker processes.search_queue_hwm_purged_(count|one)- The total number of purged objects, and the number of purged objects within the metric measurement window.search_queue_capacity- The capacity of the existing queues, expressed as a integral percentage value between 0 and 100. This measurement is based on the ratio of equeued objects and the configured high water mark.search_queue_drain_(count|one)- The total number of drain operations, and the number of drain operations within the metric measurement window.search_queue_drain_fail_(count|one)- The total number of drain failures, and the number of drain failures within the metric measurement window.search_queue_drain_timeout_(count|one)- The total number of drain timeouts, and the number of drain timeouts within the metric measurement window.search_queue_drain_latency_(min|mean|max|median|95|99|999)- The minimum, mean, maximum, median, 95th percentile, 99th percentile, and 99.9th percentile measurements of drain latency, as measured from the time it takes to initiate a drain to the time the drain is completed.search_detected_repairs_count- The total number of AAE repairs that have been detected when comparing YZ and Riak/KV AAE trees. Note that this statistic is a measurement of the differences found in the AAE trees; there may be some latency between the time the trees are compared and the time that the repair is written to Solr.search_blockedvnode_(count|one)- The total count of vnodes that have been blocked, per Riak node, and the count of blocked vnodes within the metric measurement window. Vnodes are blocked when a Solrq worker exceeds its high water mark, as defined by thesearch.queue.high_watermarkconfiguration setting.search_index_fail_(count|one)- The total count of failed attempts to index, per Riak node, and the count of index failures within the metric measurement window.search_query_throughput_(count|one)- The total count of queries, per Riak node, and the count of queries within the metric measurement window.search_query_latency_(min|mean|max|median|95|99|999)- The minimum, mean, maximum, median, 95th percentile, 99th percentile, and 99.9th percentile measurements of querying latency, as measured from the time it takes to send a request to Solr to the time the response is received from Solr.search_query_fail_(count|one)- The total count of failed queries, per Riak node, and the count of query failures within the metric measurement window.search_index_bad_entry_count- the number of writes to Solr that have resulted in an error due to the format of the data (e.g., non-unicode data) since the last restart of Riak.search_index_bad_entry_one- the number of writes to Solr that have resulted in an error due to the format of the data (e.g., non-unicode data) within the past minute.search_index_extract_fail_count- the number of failures that have occurred extracting data into a format suitable for Solr (e.g., badly formatted JSON) since the last start of Riak.search_index_extract_fail_one- the number of failures that have occurred extracting data into a format suitable for Solr (e.g., badly formatted JSON) within the past minute.
While most of the default values are sufficient, you may have to
increase search.solr.start_timeout as more data is indexed, which may cause Solr to require more time to start.